Registration for our Summer Community MeetUps is now open. Secure your slot. Register now →
Tech Deep Dive: State Machine Replication in Practice
Building Mission-Critical trading system with Aeron Cluster
At our recent Aeron MeetUp in London, Martin Thompson, co-creator of Aeron, spoke about how state machine replication can radically simplify mission‑critical trading systems while delivering extreme performance and resilience.
The session connected classic distributed-systems research with the concrete requirements of front‑office platforms: deterministic behaviour, predictable latency, and the ability to survive hardware, software, and operational failures without service interruption. Rather than treating these as competing goals, the talk shows how state machines and a replicated log can make them mutually reinforcing.
Watch the recording here
Introducing deterministic state machines
At the core is a simple idea: a deterministic state machine that maintains local state and processes a totally ordered stream of events. Incoming events are applied one-by-one; each may change state and emit further events, but given the same event sequence the outcome is always the same. System behaviour emerges from the combination of state and behaviour in the same place, rather than from a tangle of remote calls and database operations scattered across services.
This model stands in sharp contrast to a typical microservice architecture, where services call each other synchronously and rely heavily on remote databases. In that world, every network hop adds latency and failure modes, and concurrency concerns leak into business logic.
A single-threaded, in‑memory state machine avoids most of this complexity. Interaction is naturally asynchronous and event‑driven, and there is no shared-memory contention to reason about. With code and data structures kept close together, the focus shifts back to the domain problem instead of infrastructure plumbing.
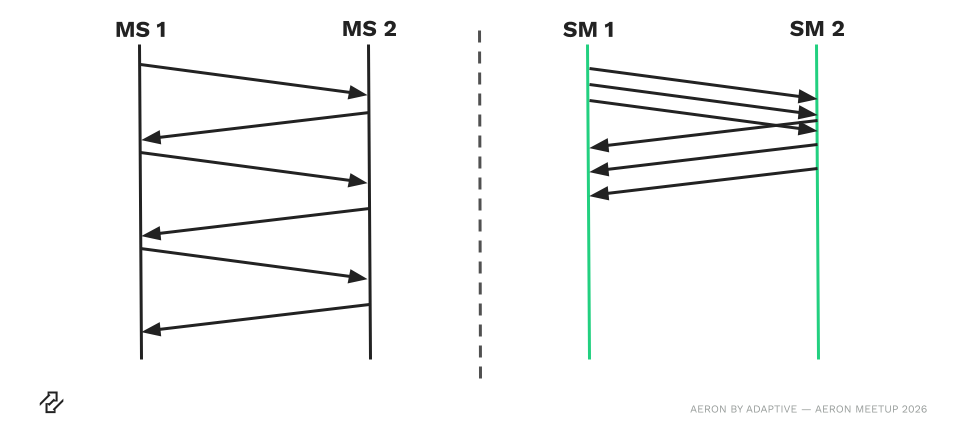
The Humble State Machine
Diagram comparing synchronous microservices (MS1, MS2) with event-driven state machines (SM1, SM2), showing how overlapping state-machine pipelines let more work be done in less time than blocking request/response calls.
From state machines to replicated system design
On its own, a single state machine on one node is not sufficient for a trading venue or pricing engine that must be ‘always on’. To achieve true fault tolerance, Martin quotes the work of Barbara Liskov, Jim Gray, Leslie Lamport, and others on state machine replication and consensus.
The pattern is straightforward: run multiple replicas of the same deterministic state machine and feed each of them an identical, totally ordered log of events. If all replicas see the same input sequence, they converge on the same state. When a node crashes or disappears, another replica can take over without losing correctness.
Aeron Cluster and a centrally managed log
Aeron Cluster is Adaptive’s implementation of this model: a platform for running replicated state machines backed by Aeron’s high‑performance messaging and clustering capabilities. Earlier academic implementations of SMR often reported maximum throughput around a few thousand events/transactions per second.
The challenge? Deliver consensus at hundreds of thousands to millions of events/transactions per second, while keeping latencies in the low tens of microseconds on suitable networks.
A central design decision is the single shared log:
All ingress is sequenced through this central log.
The log establishes a global order of events for every service in the cluster.
State machines consume from the log, update their local state and optionally append new events back into it.
The result is serializable semantics at the system level without scattered distributed transactions or ad‑hoc locking in application code.
In theoretical discussions a single log can look like a bottleneck, but the implementation experience is different. With careful engineering, a log built on Aeron can comfortably saturate modern networks while still leaving headroom, turning that “bottleneck” into a powerful simplifying point of coordination.
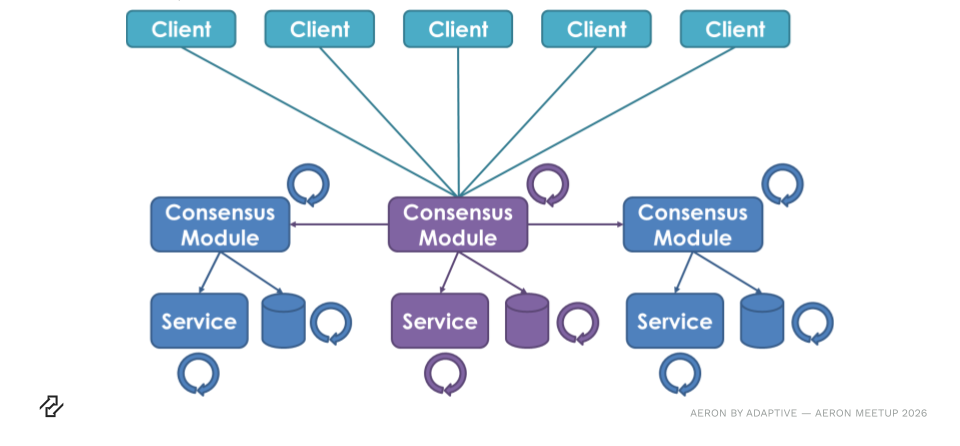
Aeron Cluster
Aeron Cluster architecture showing events being sent into a central consensus module that replicates deterministic services across nodes for high-throughput and fault-tolerant state machine processing.
Scaling through contention, coherence, and clean design
Beyond individual clusters, Martin Thompson also addresses how these ideas scale across larger systems. Using Neil Gunther’s Universal Scalability Law as a lens, it distinguished between contention—the non‑parallelisable portion of the workload—and coherence—the cost of propagating state to maintain a consistent view across nodes.
Scaling for the Enterprise
Neil Gunther’s Universal Scalability Law for “Scaling for the Enterprise”, with capacity C(N) expressed as a function of processors N and two key penalties: α for contention and β for coherence, highlighting that scalability is limited by shared work and the cost of keeping nodes in sync.
As systems spread across racks or regions, the latency of exchanging information becomes dominated by physics, particularly the speed of light.
The response is not to throw more threads at the problem but to improve design. The talk emphasised several practical tools for controlling contention and coherence cost including:
Separation of concerns.
Low coupling.
High cohesion.
Vertical scaling is framed as a utilisation problem. By profiling state machines and reducing per‑event cost, queues stay short, cores remain well-utilised and latency distributions stay tight—often a more effective route to performance than simply buying bigger hardware.
Virtual synchrony to avoid concurrency
Virtual synchrony builds on that picture. Applications run as state machines in their own right and synchronise via the log; the log gives them a shared notion of “now”, because each machine has had the same events applied up to a given point before it moves on.
When one state machine needs to read another—say a market-data generator reading an order-book state—it can just read the in-memory structures at that log position instead of firing RPCs and hoping the data hasn’t changed underneath while latency plays out.
Mission‑critical characteristics – What does it mean?
The talk also tackled the language of “mission critical” and “high availability” in concrete terms. A system is mission critical if the business cannot continue when it fails; from there, high availability breaks down into response SLAs, isolation, fault tolerance, rapid recovery, and disaster recovery, viewed across platform, operations, and applications.
Again, the log is central. Because every event is timestamped and sequenced, the platform can measure…
Round‑trip times.
Detect lagging services.
Identify anomalies such as steadily increasing processing time or growing backlogs.
That observability supports operational techniques such as blue‑green deployments and canary releases, where new versions are exercised in parallel and promoted only once they have proven themselves under real traffic.
Mission Critical – State Machine Replication
Overview of what “highly available” means for mission-critical systems, breaking it down into isolation, response SLAs, fault tolerance, rapid and disaster recovery, and safe release strategies (canary and blue-green) across platform, operations and applications.
Looking ahead: Leveraging State Machine Replication in the age of AI
State machine replication is more than a niche technique for low‑latency trading engines. It is a foundation for building platforms that are fast, observable and robust by construction, even as the surrounding ecosystem of tools and requirements continues to evolve rapidly.
In the age of AI, where large amounts of code are being generated automatically, this architecture becomes even more attractive. Instead of spraying AI-generated logic across multi-threaded microservices that are hard to reason about, that code can be wrapped inside single-threaded state machines with clear interfaces, tracked outputs, strong invariants and solid tests, all driven from a replayable log that can help understand why a decision was made.
Martin Thompson Co-creator of Aeron Adaptive | Aeron
Martin is a Java Champion with 30+ years of experience building complex and high-performance computing systems. He is most recently known for his work on Aeron and SBE. Previously at LMAX he was the co-founder and CTO when he created the Disruptor. Prior to LMAX Martin worked for Betfair, content companies with the world’s largest catalogues, and some of the most significant C++ and Java systems of the 1990s.
He can be found giving training courses on performance and concurrency, and distributed systems when he is not cutting code to make systems better. X:@mjpt777
Further reading
Technology Aeron Sequencer
Aeron Sequencer brings proven state machine replication architecture to capital markets. Explore Aeron Sequencer or join the early access program.